


Тekst je deo serijala zasnovanog na istraživanju sprovedenom među 302 visokoobrazovana ispitanika u Srbiji o načinima korišćenja i stepenu poverenja u velike jezičke modele (Large Language Models – LLM) poput ChatGPT-a, Grok-a i Claude-a.
Cilj istraživanja odnosio se na ispitivanje učestalosti korišćenja velikih jezičkih modela u svakodnevnom životu i pri donošenju važnih odluka, iskustava korisnika sa netačnim odgovorima, navika provere informacija, kao i poređenje poverenja u AI sa poverenjem u stručnjake, porodicu i tradicionalne izvore informacija.
Dobijeni rezultati pružaju uvid u to kako visokoobrazovani korisnici u Srbiji koriste ove alate i koji činioci utiču na njihovo poverenje i oslanjanje na sisteme veštačke inteligencije.
Laži, laži, laži me, ti to radiš najbolje!
Iako je svest o ograničenjima velikih jezičkih modela široko rasprostranjena, njihova svakodnevna upotreba ne opada. Istraživanje pokazuje da su većini korisnika veliki jezički modeli u prošlosti davali netačne odgovore i informacije. Istovremeno, određeni broj ispitanika ističe da ih i dalje koristi i da se oslanja na njihove savete, što postavlja jedno od ključnih pitanja današnjeg odnosa prema veštačkoj inteligenciji: ukoliko korisnici znaju da LLM-ovi nisu uvek pouzdani, zašto i dalje prihvataju njihove savete i koriste ih pri donošenju odluka?
Korisnici ne idealizuju veštačku inteligenciju
Velika većina ispitanika navodi da je u prošlosti dobila netačan odgovor od LLM-a, dok mali procenat ispitanika kaže da nema takvo iskustvo. Drugim rečima, greške nisu retka pojava.
Istovremeno, nešto više od polovine ispitanika smatra da LLM često daje netačne odgovore, dok se gotovo četvrtina sa tim ne slaže. Ovaj podatak pokazuje da korisnici ne idealizuju sistem, svesni su da modeli mogu da pogreše i da to nije izuzetak.
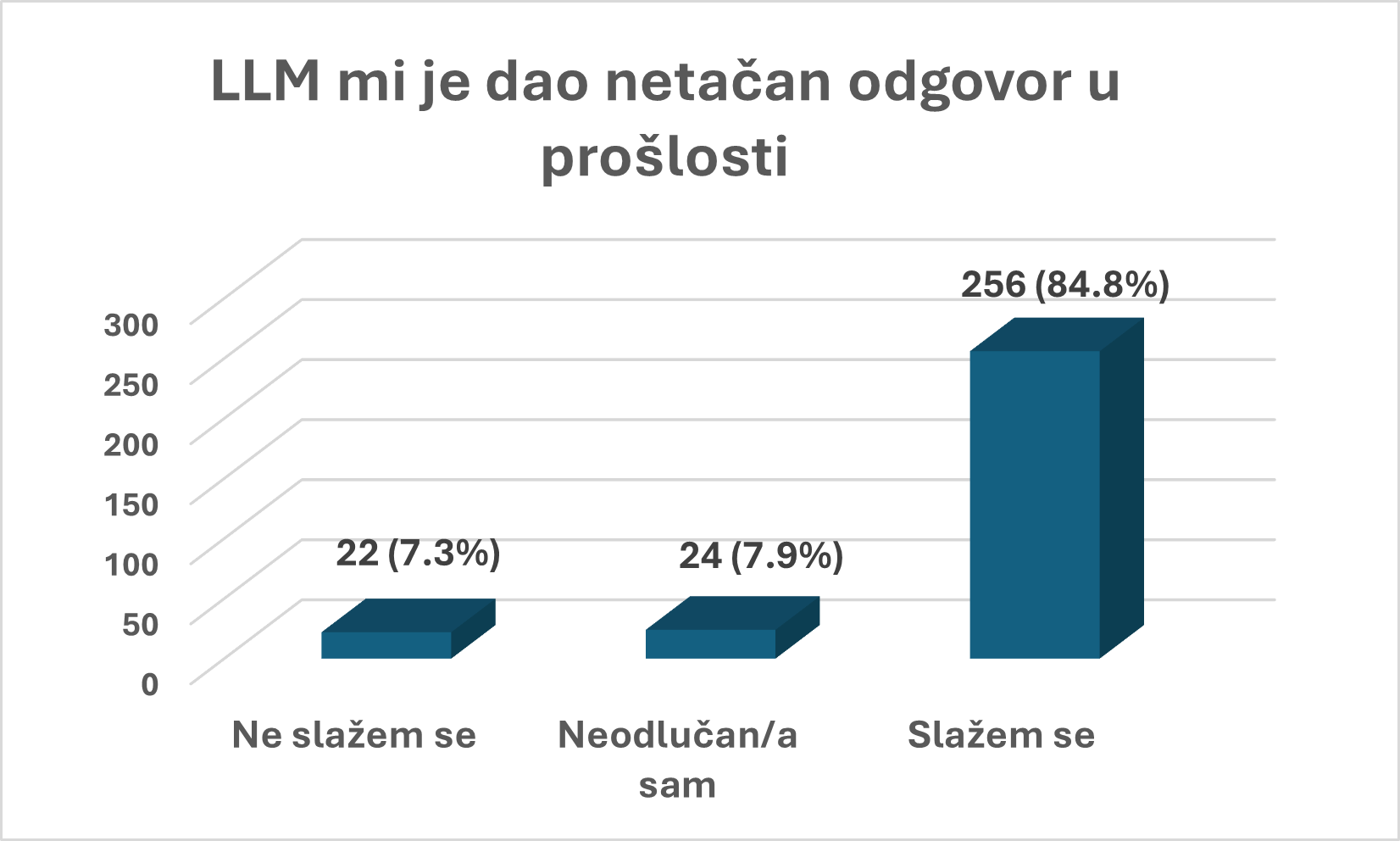
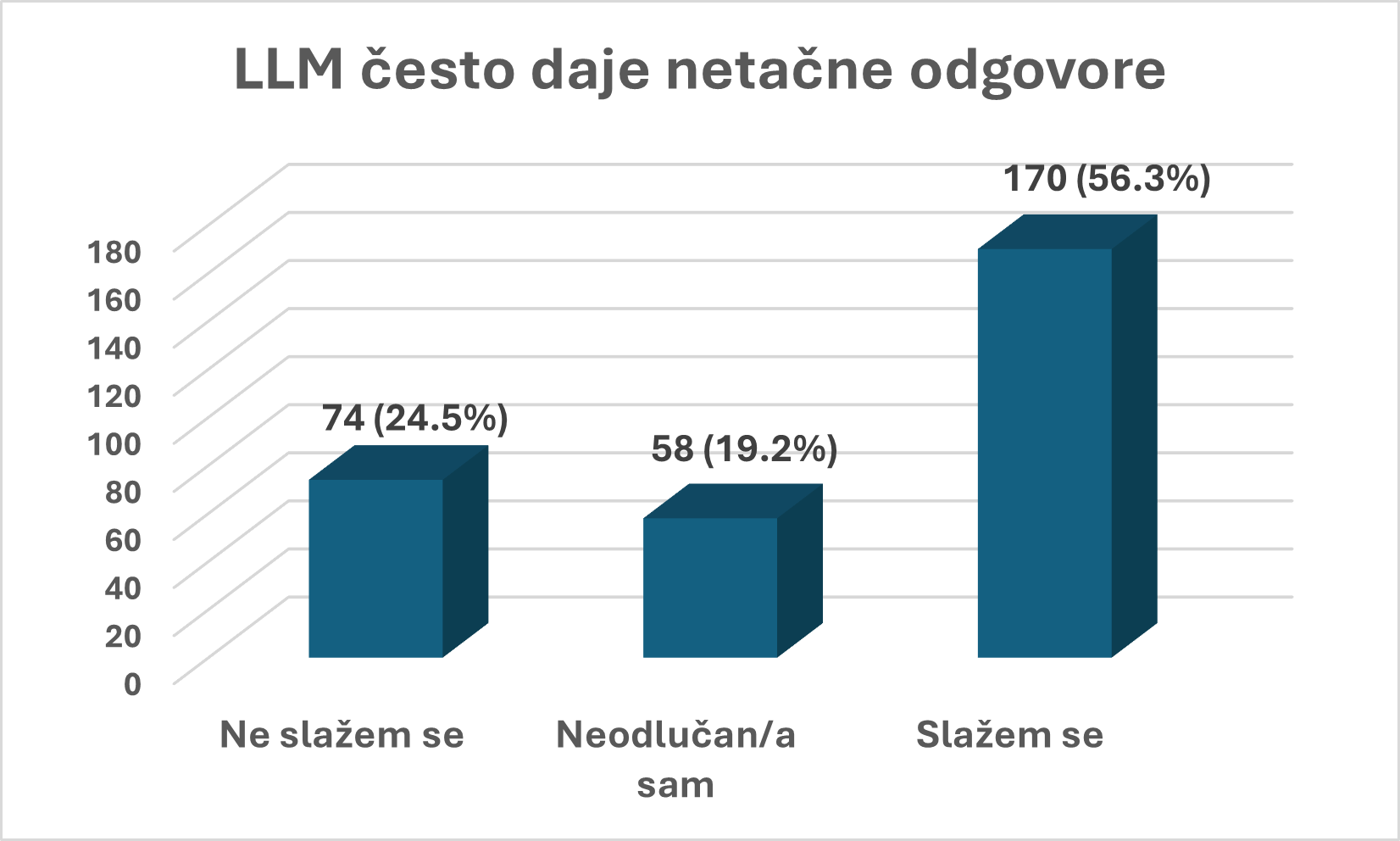
Odgovori se značajno razlikuju u zavisnosti od starosne grupe. Najveći procenat onih koji su prepoznali netačne odgovore zabeležen je u grupi od 35 do 54 godine (89,9%), zatim među starijima od 55 godina (81,6%), dok je najniži procenat u najmlađoj starosnoj grupi od 18 do 34 godine (76,9%). Sličan obrazac uočljiv je i kod percepcije učestalosti grešaka.
Stariji korisnici, naročito oni sa dugogodišnjim radnim stažom, uočavaju greške, pojednostavljenja ili izmišljene reference. Njihovo znanje i iskustvo im omogućava da prepoznaju takozvane „halucinacije“ – situacije u kojima model generiše uverljiv, ali netačan sadržaj. Mlađi korisnici, iako tehnološki veštiji, možda nemaju uvek dovoljno stručnog ili životnog iskustva da bi svaku netačnost odmah prepoznali.
Dobijeni podatak je od izuzetnog značaja jer pokazuje da svest o greškama postoji. Problem se, međutim, ne završava na tome – pitanje je kako ta svest utiče na dalju upotrebu modela veštačke inteligencije.
Kada laž zvuči kao istina
Posebno zabrinjava to da više od polovine ispitanika smatra da netačni odgovori LLM-a deluju uverljivo i pouzdano, dok se sa tim ne slaže samo svaki deseti ispitanik. Dakle, problem nije samo u tome što model greši, već u tome što greška često ne izgleda kao da je greška.
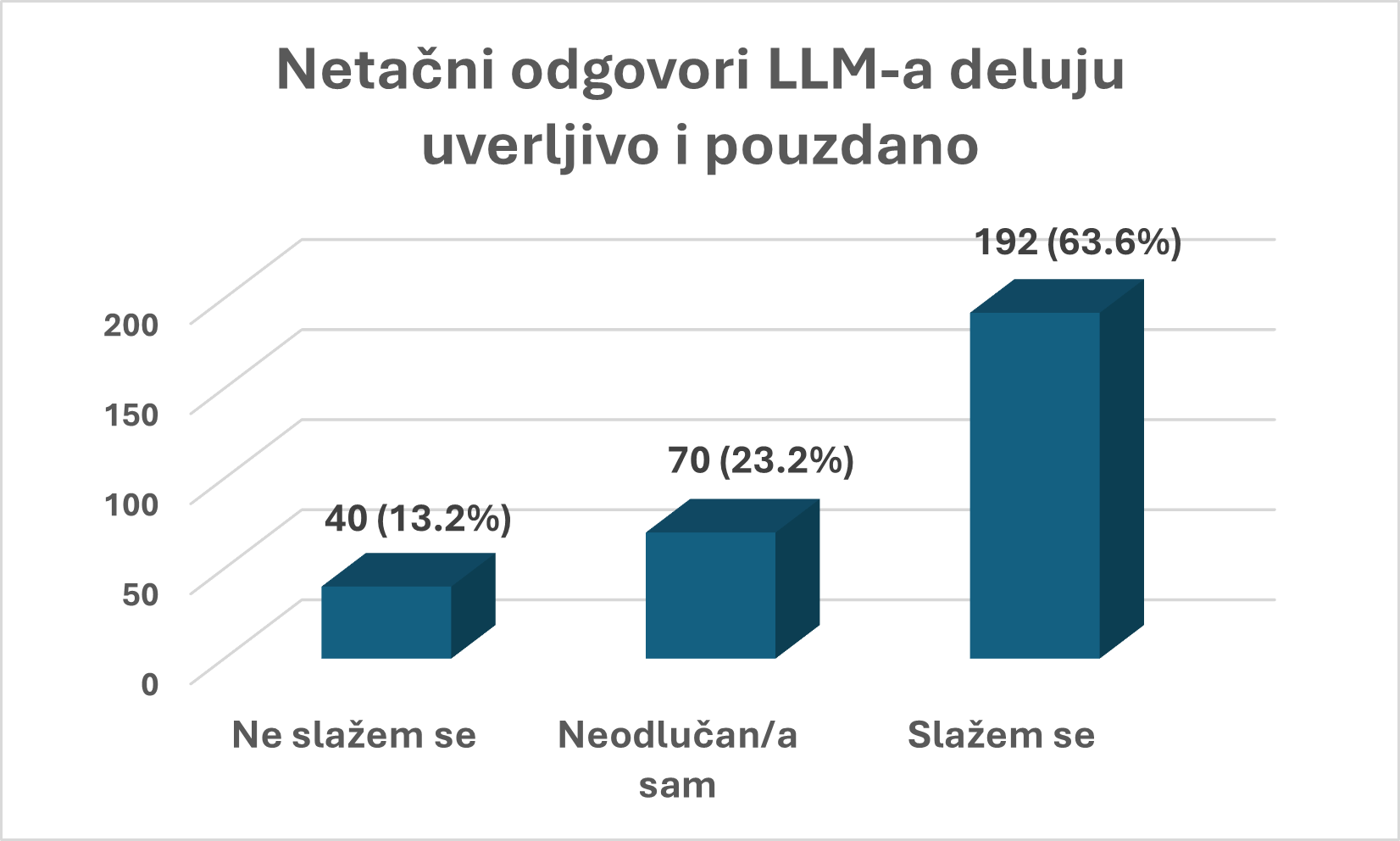
Jedan od razloga je samouverenost kojom modeli odgovaraju. LLM-ovi retko kažu „ne znam“, „nisam siguran“ ili „ovo je samo pretpostavka“, osim ako ih eksplicitno ne naterate. Uvek iznose tvrdnje odlučno, bez kolebanja, kao da su apsolutni autoritet. Ljudi su evoluciono navikli da samouveren nastup povezuju sa znanjem i kompetencijom: ko govori smireno i bez oklevanja, deluje kao da zaista zna o čemu priča. Taj obrazac ponašanja primenjujemo i u komunikaciji sa mašinom.
Drugi razlog je potpuno odsustvo „crvenih zastavica“ koje kod ljudi instinktivno primećujemo. Kada neko nije siguran ili pokušava da sakrije neznanje, obično okleva, koristi reči poput „možda“, „čini mi se“, „verovatno“, menja ton, crveni, ne gleda nas u oči i pokazuje nelagodu. Kod LLM-a tih signala nema, što nam ne daje povod za sumnju, pa netačnost lako prolazi neprimećena.
To je ono što se često naziva „fluent bullshit“ (srp. elokventno izrečena besmislica), modeli zvuče autoritativno čak i kada greše, a visok procenat korisnika koji im veruje uprkos saznanju o ograničenjima potvrđuje strahove stručnjaka od mogućeg širenja dezinformacija na nov, suptilniji način.
Treći razlog je i efekat očekivanja (eng. expectancy effect). Kada se obratimo modelu za savet ili objašnjenje, već unapred pretpostavljamo da će odgovor biti koristan i tačan jer je alat upravo za to dizajniran.
Zašto tolerišemo greške?
Iako je većina ispitanika svesna da LLM može da pogreši, to ih ne sprečava da se na njegove savete oslanjaju. Polovina anketiranih navodi da se, uprkos svesti o mogućim greškama, oslanja na odgovore modela. Pored toga, više od trećine ispitanika nastavlja da koristi ove modele za važne odluke, čak i nakon što je dobilo netačan odgovor.
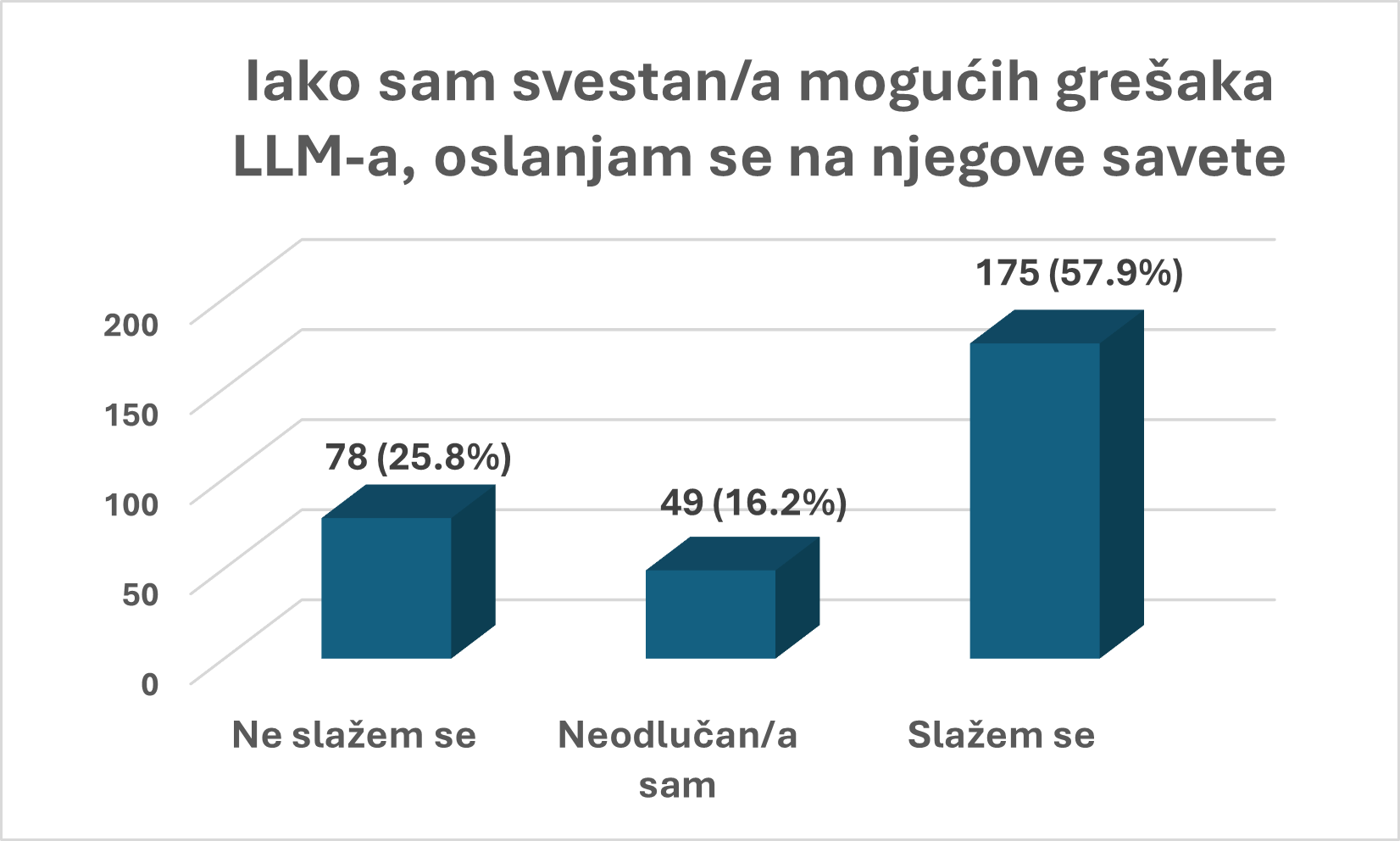
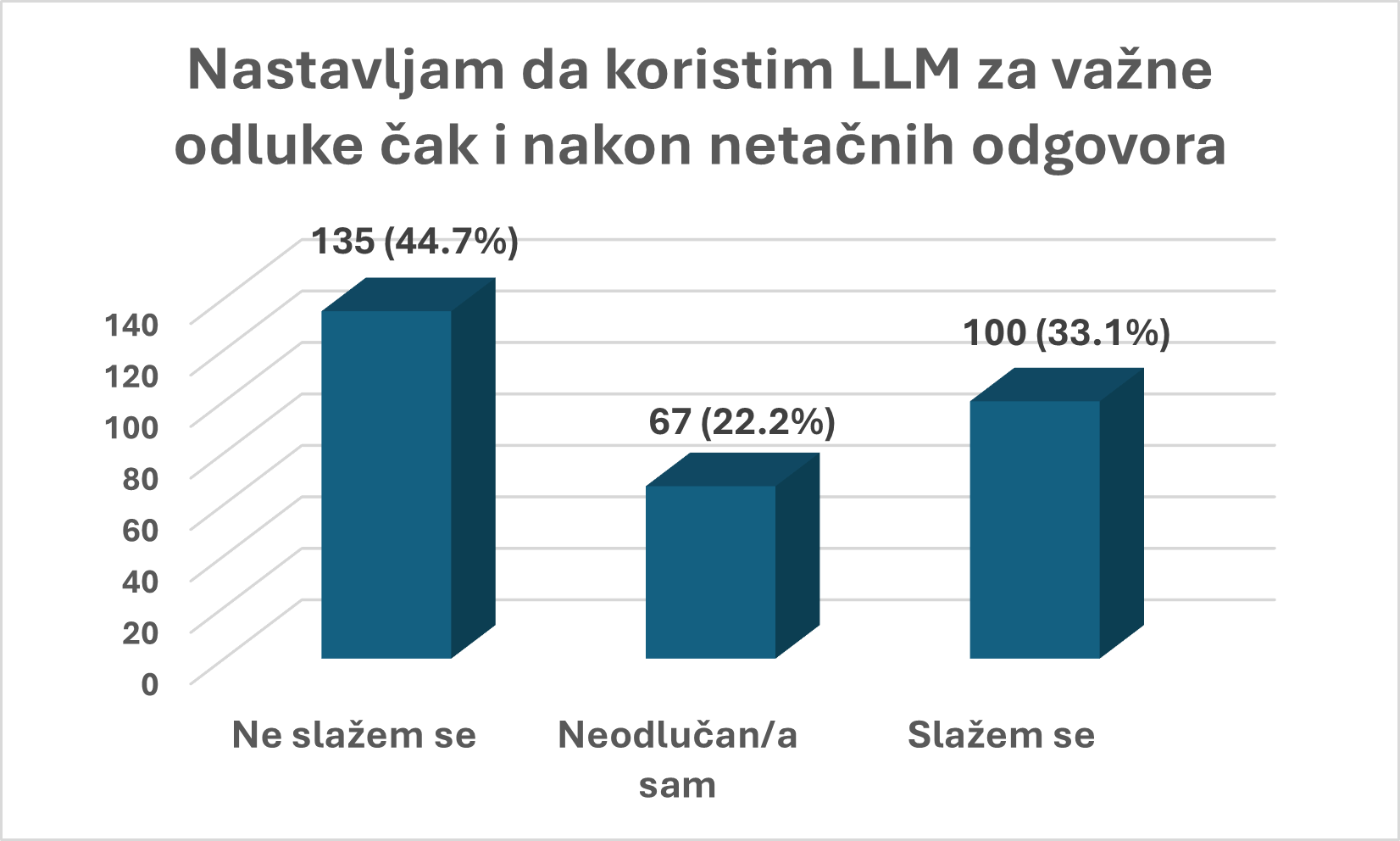
Ovaj rezultat pokazuje da odnos korisnika prema veštačkoj inteligenciji nije zasnovan na iluziji nepogrešivosti. Ljudi ne očekuju da LLM bude savršen, oni ga koriste zato što su svesno napravili pragmatičnu računicu: korist daleko nadmašuje rizik.
Model pruža odgovore neverovatnom brzinom, uvek je dostupan i daje detaljna, strukturirana objašnjenja. Za ogroman spektar svakodnevnih situacija: od pisanja mejla, preko objašnjenja pojma, recepta, ideja za putovanje, jednostavnih prevoda, pa do brzog brainstorming-a, korist je ogromna, a posledice eventualne greške najčešće zanemarljive ili lako popravljive.
U pozadini stoji klasična cost-benefit kalkulacija (šta dobijam, a šta gubim): čak i ako model pogreši u 10–20% slučajeva, u preostalih 80–90% štedi sate vremena i truda. Ljudi to intuitivno osećaju i zato nastavljaju da koriste alat uprkos poznatim manama.
Vremenom se formira tzv. zavisnost od udobnosti (eng. convenience bias). Kada se naviknete da odgovor dobijete za nekoliko sekundi, povratak na pretraživanje više sajtova, čitanje opširnih tekstova ili čekanje odgovora od kolega postaje psihološki naporno, dok istovremeno raste tolerancija prema nesavršenostima i netačnostima koje generišu LLM modeli. Tu je i tzv. iluzija kontrole (eng. illusion of control), koja igra veliku ulogu. Mnogi korisnici veruju da su dovoljno pametni i kritični da sami prepoznaju kada odgovor „ne pije vodu“.
Sve u svemu, ovo nije priča o naivnosti i poverenju, već o realnom, svesnom kompromisu: koristimo velike jezičke modele ne zato što su savršeni, već zato što su dovoljno dobri da promene način na koji razmišljamo i radimo, štede nam vreme, energiju i novac i, na kraju krajeva, olakšavaju nam život.
Autor: Milena Šović, AI Implementation Specialist & AI Content Trainer
Foto: Pixabay